Additional Experiments
Larger Input View Gaps
We evaluate novel-view synthesis quality under varying context view gaps (10, 20, 30, 40 frames apart) on the DL3DV test set. For each gap, 2 context views are used and 4 target views are sampled evenly within the range. LGTM consistently outperforms the NoPoSplat baseline across all gaps and produces noticeably sharper details even at large viewpoint differences. See more details in the paper's supplementary material.
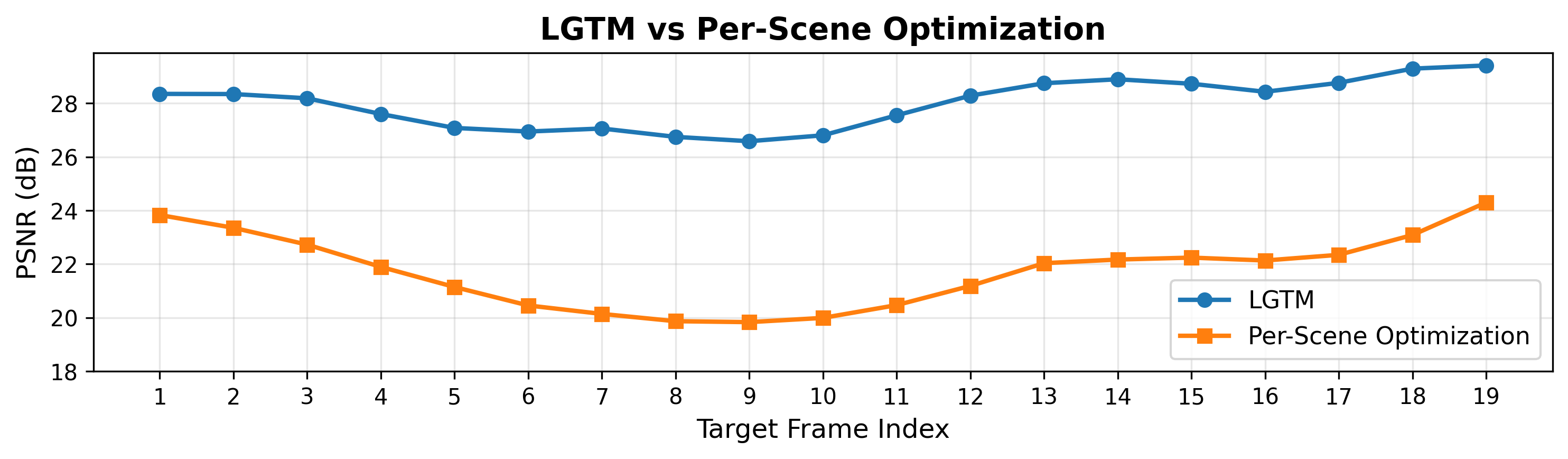
VS Per-Scene Optimization
Per-scene optimized 3DGS overfits to context views and struggles to generalize to novel viewpoints, while LGTM's learned priors produce fewer edge artifacts and more stable quality across all target frames. LGTM also reconstructs in ~0.5s vs. ~30 minutes for per-scene optimization. Both methods use frames 0 and 20 as context and frames 1-19 as targets. See more details in the paper's supplementary material.
VS Super-Resolution (SR)
An alternative to achieve 4K rendering is to apply image super-resolution on low-resolution Gaussian renderings. However, SR introduces hallucinated details, temporal flickering, and significant computational overhead. LGTM achieves sharper, geometrically consistent results at a fraction of the cost. See more details in the paper's supplementary material.